
↯


As part of human core knowledge, the representation of objects is the building block of mental representation that supports high-level concepts and symbolic reasoning. While humans develop the ability of perceiving objects situated in 3D environments without supervision, models that learn the same set of abilities with similar constraints faced by human infants are lacking. Towards this end, we developed a novel network architecture that simultaneously learns to 1) segment objects from discrete images, 2) infer their 3D locations, and 3) perceive depth, all while using only information directly available to the brain as training data, namely: sequences of images and self-motion. The core idea is treating objects as latent causes of visual input which the brain uses to make efficient predictions of future scenes. This results in object representations being learned as an essential byproduct of learning to predict.
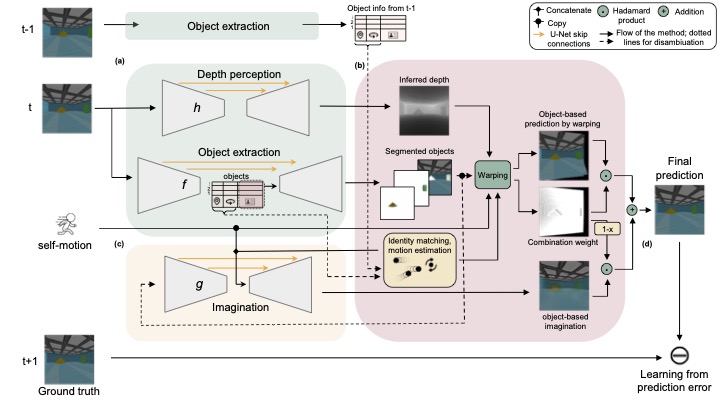
The model includes three networks for depth perception, object extraction and imagination, and uses two frames \( \mathbf{I}^{(t-1)} \) and \( \mathbf{I}^{(t)} \) to predict the next frame \( \mathbf{I}^{(t+1)} \). (a) From \( \mathbf{I}^{(t)} \), the frame at time \( t \), object extraction network \( f \) outputs the location, pose, an identity code (from the encoder) and a probabilistic segmentation map (from the decoder) for each object. Depth perception network \( h \) infers a depth map. Object location, pose and identity code are also extracted from \( \mathbf{I}^{(t-1)} \). (b) All objects between frames are soft-matched based on the distances between their identity codes. Motion information of each object is estimated using the spatial information inferred for it at \( t-1 \) and \( t \) and the observer's motion. Motion information of self and objects are used together with object segmentation and depth maps to predict \( \mathbf{I}^{(t+1)} \) by warping \( \mathbf{I}^{(t)} \). (c) The segmented object images and depth at \( t \), together with all motion information, are used by the imagination network to imagine \( \mathbf{I}^{(t+1)} \) to fill the regions not predictable by warping. (d) The error between the final combined prediction and the ground truth of the next frame \( \mathbf{I}^{(t+1)} \) provides major teaching signals for all networks.

@misc{day2024learning,
title={Learning 3D object-centric representation through prediction},
author={John Day and Tushar Arora and Jirui Liu and Li Erran Li and Ming Bo Cai},
year={2024},
eprint={2403.03730},
archivePrefix={arXiv},
primaryClass={cs.CV}
}